
背景知识
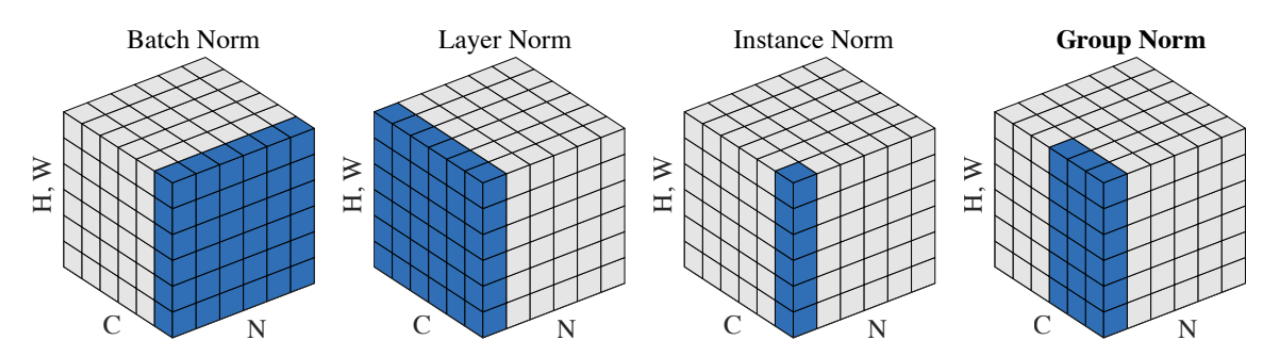
LayerNorm
attention
- additive attention 可以处理维度不同的情况
- dot-product attention 维度一样
transformer
流程
- embedding 把单词转为512维向量,可以随机初始化或者word2vector
结构
- 卷积难建模长序列-》attention可以看到全部像素
- 卷积可以多个通道-》multi-head
- 自注意力机制
- 自回归
- 编码器
- 6层一样的
- multi-head self-attention
- LayerNorm(x+sublayer(x))
- position-wise fully connected feed-forward network(MLP)
- LayerNorm(x+sublayer(x))
- 6层一样的
- 解码器
- 6层一样的
- masked multi-head self-attention 【避免看到全部】
- LayerNorm(x+sublayer(x))
- multi-head self-attention
- LayerNorm(x+sublayer(x))
- position-wise fully connected feed-forward network(MLP)
- LayerNorm(x+sublayer(x))
- 6层一样的
- multi-head self-attention
- scaled dot-product attention
- 8 head
