
背景知识
- diffusion model扩散模型分为去噪扩散概率模型 (DDPM) 和基于分数的生成模型 (SGMs),两者融合为score-based diffusion models
- SGMs
-
Generative Modeling by Estimating Gradients of the Data Distribution,2019
-
Learning Energy-Based Models in High-Dimensional Spaces with Multi-scale Denoising Score Matching,2019
-
Improved techniques for training score-based generative models,2020
-
Adversarial score matching and improved sampling for image generation,2021
-
- 融合:
- Denoising diffusion implicit models,2020
- Gotta go fast when generating data with score-based models,2021
- Progressive distillation for fast sampling of diffusion models,2022
- Pseudo Numerical Methods for Diffusion Models on Manifolds,2022
- Tackling the generative learning trilemma with denoising diffusion GANs,2022
- 绿色表示diffusion模型
- 2015
- DeepDream【2015,Google】
- 2017
- VQ-VAE【Deep Mind】
- 2020
- [1] 【Google,基于diffusion】
- GPT-3 【OpenAI】
- 2021
- DALL-E[^DALL-E]【2021,OpenAI,基于VQ-VAE】
- 非官方实现 https://github.com/lucidrains/DALLE-pytorch 12B 参数
- DALLE-mini https://github.com/borisdayma/dalle-mini
- DALLE mini 使用预训练好的模型(VQGAN、BART,CLIP),而 DALLE 从头开始训练;训练数据对数 15M vs. 0.25B
- 0.4B 参数,媒体:https://www.leiphone.com/category/academic/lrCG1TvFt2SuHAuv.html
- CogView【中文,基于VQ-VAE,4B参数】
-
- CLIP+Guided Diffusion
- https://github.com/alembics/disco-diffusion
- VQGAN 【2021, Stable Diffusion作者】
- wenkan 【基于VA-GAN】
- nuwa 【基于VQ-GAN】
- Guided Diffusion[^Guided Diffusion] 【 OpenAI】
- 在每一步逆扩散时,在计算高斯分布的均值时加上方差和分类梯度项的乘积
- Semantic Diffusion Guidance[^Semantic Diffusion Guidance]
- 将类别引导拓展成了基于参考图引导以及基于文本引导两种形式
- Classifier-Free Diffusion Guidance【DDPM作者, Google】
- 分别计算有 y 的情况下和无 y 的条件下噪声的差,来模拟类别引导
- [2] 【OpenAI,基于diffusion】
- 将类别条件的变为以 CLIP 输出的语言条件
- https://github.com/openai/glide-text2im
- 3.5B 参数
- ernie vilg 【基于VQ-VAE】
- ofa space【基于VQ-VAE】
- DALL-E[^DALL-E]【2021,OpenAI,基于VQ-VAE】
- 2022
- 【OpenAI,基于diffusion】
- 上半部分是预训练的 CLIP
- 不是从 noise 开始逆扩散,而是从 CLIP image encoding 开始,其余类似 GLIDE,用了 up-sampling diffusion model
- 像是 GLIDE,而非 DALLE
- 大小基本同 GLIDE,*3.5B 参数
- Cogview2【基于VQ-VAE,6B参数】
- [^Stable Diffusion] 【stability.AI,基于diffusion】
- [3] 【Google,基于diffusion】
- from Google Brain,比 stable diffusion 晚,但未开源
- 用了更轻量化的 U-Net,和更强的文本编码器 T5 (11B 参数,训练中固定),对比 Stable diffusion 用的 Bert。总的来说对于文字中复杂的逻辑理解更好 https://zhuanlan.zhihu.com/p/522381808
- 同 DALLE2,用了 upsampling classifier-free diffusion
- Cogvideo【中文,基于VQ-VAE,9.4B参数】
- Parti[4] 【Google,基于VQ-GAN】
- Autoregressive model 也能达到和 diffusion model 一样好的效果(对于 256*256 的生成),再 upsampling 可以借助 diffusion model
- Imagen video
- 【OpenAI,基于diffusion】
- 其它
- latent diffusion model 压缩的不同尺寸diffusion
- Rombach, Robin, et al. “High-Resolution Image Synthesis with Latent Diffusion Models.” arXiv preprint arXiv:2112.10752 (2021)
- 二次元novelai
- latent diffusion model 压缩的不同尺寸diffusion
数学知识
ELBO 和变分推断
-
目标及背景:
想从一系列数据 x 中推理出隐变量z的分布,也即想求解条件概率:p(z|x) = p(z,x)/p(x)
其中p(z,x)可以由专家根据他们的知识给出。例如 GMM 模型中,每个点属于哪个高斯分布就是隐变量,p(z,x)代表每个点属于某一个高斯分布的概率,这个由正态分布根据距中心的距离即可给出。
但实际中,从p(x|z)积分来计算分母p(x)很困难(假设k个隐变量,积分需要k重,计算复杂度 k^n 会随着数据量 n 指数增长)。所以要用到变分推断,想用一个比较容易实现的分布q_θ(z)去逼近p(z|x)。所以在这个过程中,我们的关键点转变了,从求分布的推断问题,变成了缩小距离的优化问题。 -
用KL散度衡量两个分布的相似度:
KL(q(z)||p(z|x)) = E_q[log q_θ(z)] - E_q[log p(z,x)] + log p(x),其中ELBO(q_θ) = E_q[log p(z,x)] - E_q[log q(z)]
可以看到log p(x) = ELBO(q_θ) + KL(q(z)||p(z|x)) >= ELBO(q_θ)恒成立(KL 散度永远大于0),
所以 ELBO 叫做 Evidence Lower Bound(或 variational lower bound),也即证据下界,这里证据指数据或可观测变量的概率密度,也即log p(x) -
变分推断的过程(可以带入GMM模型方便理解)
一个例子:https://www.zhihu.com/question/41765860/answer/331070683
- 先写出
p(z,x)和q_θ(z) - 带入公式
ELBO(q_θ) = E_q[log p(z,x)] - E_q[log q(z)]
实际中,求期望这一步有挺多技巧,可能还会用到指数簇分布,用累积函数 A 的导数作为期望值:https://qianyang-hfut.blog.csdn.net/article/details/87247363 - 将
ELBO(q_θ)对θ求偏导,且使偏导等于0,最大化 ELBO
- 先写出
-
为什么叫变分推断?
其实和求泛函(最速曲线)用的变分法其实有相关性。求ELBO(q_θ)的极值需要对θ的偏导,其实相当于是对一个函数求导数
EM算法
(一般收敛到局部最优,不能确保全局最优)
EM算法分为 E-step 和 M-step。和变分推断原理一样,不断迭代提高 ELBO,直到KL散度接近于0(KL恒大于零),也即 q(z) 逼近了 p(z|x)
总结来讲 EM 算法是变分推断的一个特例,K-means是一种 EM 算法。EM 算法在 E-step 时,认为 q_θ(z) 是给定的(由于迭代更新)
- E-step:给定参数
θ_t,求出最合适的隐变量z_(t+1)
比如 k-means 中隐变量z_(t+1)确定每个点属于哪个聚类 - M-step:给定隐变量
z_(t+1),用极大似然估计来计算θ_(t+1)
比如 k-means 中的更新类中心位置,使得 distance 的 loss 最小化
VAE
Variational AutoEncoder,2014
- 目标
我们希望学习出一个模型,能产生训练样本中没有,但与训练集相似的数据。换一种说法,对于样本空间,当以抽取数据时,我们希望以较高概率抽取到与训练样本近似的数据。推理时,可以直接在隐空间采样生成图像,且根据隐变量 z 进行生成风格的调整 - 实现方法
- 网络结构上还是一个 encoder + decoder,但在 loss 的设计上在自编码器的基础上还加了一个关于隐变量的 KL loss 作为规范项
- VAE中,强制假设了隐变量
p(z)是标准正态分布,而让 encoder 的输出q(z|x)去拟合p(z),也即 KL loss。这一步也即用到了 ELBO 的公式 - 此外,为了可以反传梯度,用了一个 重参数化
Reparameterization Trick,将z~N(μ,∑)采样转变到z=μ+σ*e,其中e是从正态分布采样的,因此对于每一个 sample 可以认为是个常数,变得可微。
Stylegan_ada_pytorch
问题 Failure to load data in _seralization.py
解决:下载下来,不用url
CLIP-GEN
-
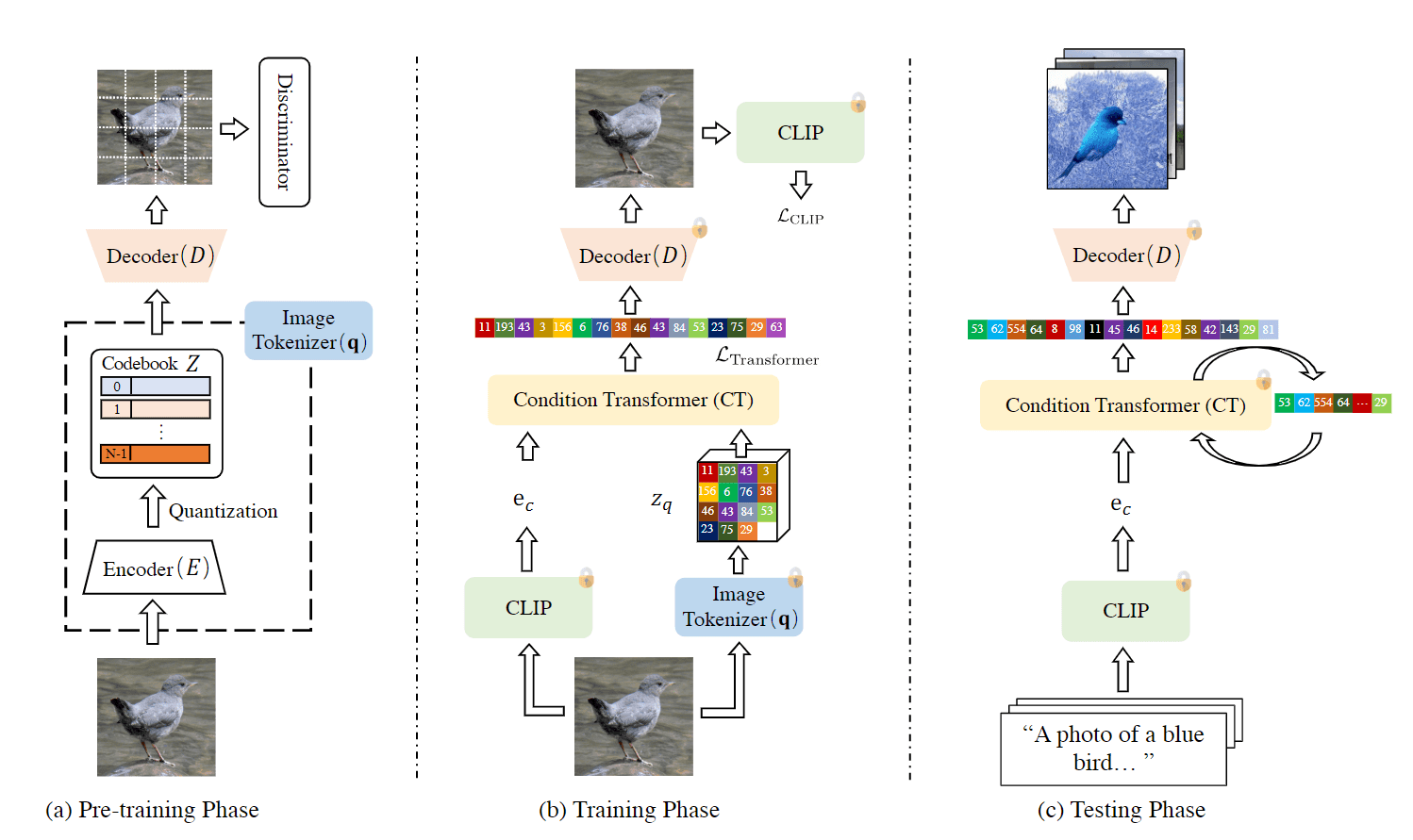
一个缝合 CLIP 和 VQGAN 的工作,优点是只用图片并借助预训练好的 CLIP 模型,也能实现 text-to-image 的网络训练,训练步骤
-
预训练 VQGAN
-
训练 condition transformer:用预训练的 VQGAN,已经能够通过 image tokens 来生成图片了。这一步是为了把 VQGAN encoder 生成的 image token 和 CLIP 对于图像的 token align 起来。因为 CLIP 本身已经实现了文本和图像 token 的 align,所以间接地把文本的 token 和 VQGAN encoder 产生的 token align起 来了。 训练的过程中 VQGAN 和 CLIP 参数都保持不变
-

DALL-E
训练dVAE,得到32x32=1024的编码+256BPE-encoded text tokens-》自回归transformer-》排序-CLIP检索
https://zhuanlan.zhihu.com/p/394467135

-
VQ-VAE:隐空间是离散的 VAE
- 选取与 cookbook 中与 encoder 输出的 embedding 最接近的那个。但会带来不可导的问题(无法像 VAE 那样可以重参数化)。DALLE 用 Gumbel Softmax trick 来解决这个问题(简单来说就是arg max不可导,可以用 softmax 来近似代替 max,而 arg softmax 是可导的)
-
训练阶段:(参数可能有出入)
-
Stage One 先单独做 dVAE 的训练(得到encoder、visual codebook、decoder)。
1
256x256
的图片先被 encoder 处理成 latent space
1
32x32xD
,也即分成
1
32x32
个 patch,每个 patch 都由一个 D 维的 token 表示(这里 D 就是 codebook 的尺寸,DALLE 用的 512)。每个 D 维的向量都能在词汇量为 8192 的 codebook 中找到一个最邻近的一个 token,然后变成 one-hot coding:
1
32x32x8192
。这 1024 个图像 token 会和 text token 汇合,汇合处理后,decoder 还原图像
- 这里说 token 就是指长度为 512 的向量
- 8192 是 image 的 codebook 大小,文本是 16384
-
Stage Two,固定 dVAE,text 和 image 分别做编码,concat 在一起之后(text 得到 256 个 token,和 32x32 个 image 一起共 1280 个)做类似 GPT-3 的 autoregressive
-
-
推理阶段:只输入 text
-
BPE Encoder 会生成 text 的 token
-
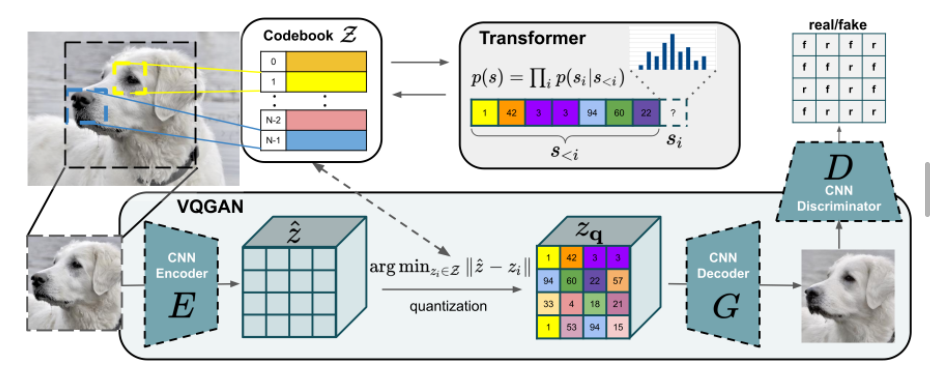
图像生成过程和下图 VQGAN 有点类似(不同是 DALLE 有来自文本的 token,且 DALLE 用的 VQVAE)
-
基于文本的 token 和已经得到的 image patch 的 token,会过一个 transfomer,生成一个 logits,这个 logits 会决定从 codebook 中选哪个 token。如此往复,直至所有 image token 都被生成好(也即图像后生成的像素其实也取决于先生成的像素)
-
VQGAN 的 Transformer 为 GPT-2
-
-
按 patch 采样完毕,通过 decoder
-
DALLE 用了 CLIP 用于选择最佳生成的图像
-
DDPM(Denoising Diffusion Probabilistic Model)
原理

- 加噪过程/向前过程:data->noise,逆过程:noise->data,latent code和原图同尺寸。
重参数reparameterization trick
- 从高斯分布采样,过程不可导,需要通过独立随机变量加以引导,和 可以通过参数的神经网络推导,这样采样过程可以梯度求导。
前向过程Forward Diffusion Process(FDP)
- 图像通过次添加高斯噪声,得到,最终是标准正态分布?,每个时刻只和相关,可看做马尔科夫过程:
逆过程Reverse Diffusion Process(RDP)
- 当,逆过程也可以近似认为是高斯分布。值得注意的是,当为条件时,可以通过贝叶斯公式得到,把逆向过程变回前向。最后使用参数的神经网络预测逆向分布。
Score-Based Generative Modeling through Stochastic Differential Equations
- 展开对应的高斯概率密度函数,从而得到和的值。
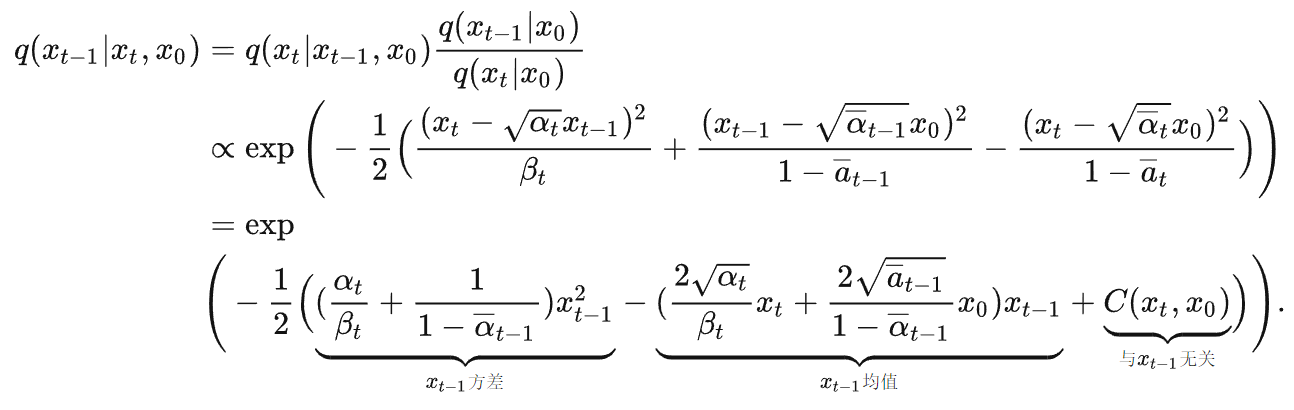
- 其中高斯分布为神经网络所预测的噪声,可看作。
- 简而言之,和->->->重参数->
损失函数
- 输入,从1~T随机采样t,从标准高斯分布采样噪声,得到
- 和通过unet得到
- 计算和的损失
-
为了求
p_θ,DDPM最大化其似然估计:log p_θ(x_0)。下图是省略版的思路(怎么从最大化似然估计到最小化平方差loss),其中会用到上面求的μ_t,具体推导见:https://zhuanlan.zhihu.com/p/558462214
-
网络训练方法如下,上面公式推导的
ε_θ(...)一项就代表的是 U-Net 网络,loss定义如下: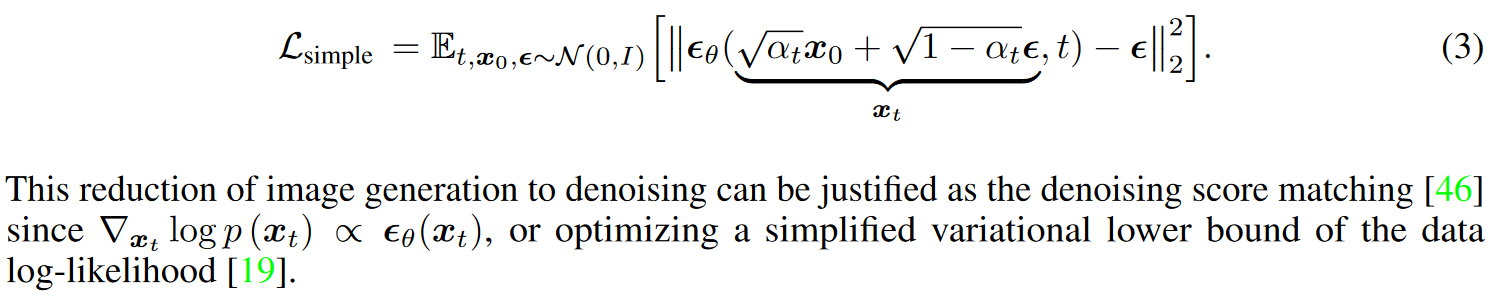
也即在已知 x_0 和 ε (也即 x_t)的情况,用 U-net 去拟合 ε(每一个时间 t 网络都是复用的,类比RNN)。Sampling 阶段第 4 行的由来见上面推导的公式浅蓝色部分




Stable Diffusion
相比原始diffusion,优点是用 encoder 将 image 从原始 pixel space 映射到 latent space,减少了计算量。因为 diffusion model 偏向进行 semnatic compression(人眼易察觉的),GAN/AutoEncoder 这些偏向进行 perceptual compression(也就是人眼很难察觉到高频信息),所以可以先用 encoder 对图像类似进行一个低通滤波。Endocer 能有效地将图像边长缩小到原来的 1/4 到 1/16,在生成的样本质量上甚至还有提升。
方法上,首先预训练一个 autoencoder,然后在多个diffusion model的训练,这个autoencoder 都可以复用。 开源的模型在 LAION-400M(Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs) 数据集上训练,模型大小5.7GB,对应 1.45B 参数。
推理:在1个 V100 GPU day 大概能推理10000张,每一张大概 8s;训练在30个V100 day就差不多了,相比之前的需要150-1000个,大幅降低了。

下载模型
issues
https://github.com/CompVis/stable-diffusion/issues/49跳转到下面228
Github issues 和 模型脚本?
https://github.com/huggingface/diffusers/issues/228
ckpt版本:
https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
官网下载clip和taming-transformers放到src下面
然后再stable_diffusion, clip, taming-transformers下面pip install -e .
安装新镜像
Ssh
Conda
问题
RuntimeError: Sizes of tensors must match except in dimension 1. Expected size 16 but got size 15 for tensor number 1 in the list.
需要:512
Cuda out of memory
图像尺寸太大
代码
Imagen Video
VDM
原理
生成过程
- 随机生成
- 和生成
- 和生成
- 和得到
损失函数
- 输入,从1~T随机采样t,从标准高斯分布采样噪声,得到
- 和通过unet得到
- 计算和的损失
MCVD(Masked Conditional VIdeo Diffusion)
动机:
视频预测现有方法生成质量差,且难泛化
现有方法只能视频预测,不能同时实现无条件生成、插值任务
发展
-
视频预测帮助决策?
-
视频预测方法
- spatio-temporal derivatives时空导数、optical flow光流、recurrent blocks循环块.
- Scaling Autoregressive Video Models,2019
- High fidelity video prediction with large stochastic recurrent neural networks, 2019
- Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction, 2020
- FitVid: Overfitting in Pixel-Level Video Prediction,2021 【提高参数效率】
-
数据集
- Cityscapes:The Cityscapes Dataset for Semantic Urban Scene Understanding
原理
MCVD:以块方式屏蔽过去和/或未来帧,实现视频预测、无条件生成、视频插值。
- probabilistic conditional score-based denoising diffusion model, conditioned on past and/or future frames 基于过去和/或未来帧的概率条件分数去噪扩散模型
- 基于随机独立,以块方式屏蔽过去和/或未来帧的调节过程,使单个模型能够解决多个视频任务:未来/过去预测、无条件生成和插值
- 简单的非循环 2D 卷积架构构建,以帧块为条件并生成帧块
- 以滑动窗口逐块自回归快速生成任意长度、连贯的长视频
- 卷积网络U-net+SPAce-Time-Adaptive Normalization(SPATIN)
结论
- 标准视频预测、插值基准测试 SOTA
- 合成长期帧表现好
- ≤ 4 个 GPU 1-12 天
下载
https://www.dropbox.com/s/ge9e5ujwgetktms/i3d_torchscript.pt
模型
https://drive.google.com/drive/folders/15pDq2ziTv3n5SlrGhGM0GVqwIZXgebyD
数据
参考
https://zhuanlan.zhihu.com/p/520574254
https://mask-cond-video-diffusion.github.io/ blog
MAKE-A-VIDEO
MoCoGAN-HD
CogVideo
Video Diffusion Models
let it Flow
Transframer: Arbitrary Frame
Endless Loops:
https://sites.google.com/view/transframer
diffusion
https://zhuanlan.zhihu.com/p/546311167
https://www.51cto.com/article/718616.html
https://zhuanlan.zhihu.com/p/573407864
https://zhuanlan.zhihu.com/p/128809461
https://zhuanlan.zhihu.com/p/341524475 VAE
https://imagen.research.google/video/
https://www.cnblogs.com/MTandHJ/p/15698607.html
https://zhuanlan.zhihu.com/p/550967884
https://www.zhihu.com/question/530608581/answer/2608721843
https://zhuanlan.zhihu.com/p/549623622
https://zhuanlan.zhihu.com/p/532402983
https://www.51cto.com/article/718616.html
https://www.zhihu.com/question/536012286
https://zhuanlan.zhihu.com/p/573984443
https://www.youtube.com/watch?v=qpiSlo0gsp4
https://zhuanlan.zhihu.com/p/520574254
https://zhuanlan.zhihu.com/p/562226867
https://towardsdatascience.com/generative-ai-878909fb7868
https://www.zhihu.com/question/545764550/answer/2670611518
http://marvolo.top/archives/45716
https://zhuanlan.zhihu.com/p/572161541
https://blog.csdn.net/qq_39388410/article/details/126576756
https://zhuanlan.zhihu.com/p/546311167
https://zhuanlan.zhihu.com/p/573407864 [imagen video
https://techcrunch.com/2022/10/05/google-answers-metas-video-generating-ai-with-its-own-dubbed-imagen-video/] [imagen video
https://ai-scholar.tech/zh/articles/video-generation%2Fcogvideo [cogvideo
]
参考
- https://zhuanlan.zhihu.com/p/560645985 【介绍了各种工作的blog】
- https://zhuanlan.zhihu.com/p/525106459 【详细介绍DDPM公式】
- https://zhuanlan.zhihu.com/p/449284962
参考文献
[^Guided Diffusion]:Diffusion Models Beat GANs on Image Synthesis
[^Semantic Diffusion Guidance]:More Control for Free! Image Synthesis with Semantic Diffusion Guidance
Denoising Diffusion Probabilistic Models ↩︎
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
[^Stable Diffusion]:High-Resolution Image Synthesis with Latent Diffusion Models ↩︎Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding ↩︎
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation ↩︎
