
背景知识
大规模预训练就是在大规模宽泛的数据上,通过设计无监督的代理任务,训练一个foundation model(基础模型),获得很强的backbone,通过zero-shot,few-shot,finetune等方式能适应其它下游任务。它是一种表示学习方式(表示又称表征、特征)。
表示学习以前发展:人工、PCA、矩阵分解、cluster、概率图模型、深度学习Imagenet初始化
-
大规模预训练的优点:
-
通用性、泛化性
-
模型越大效果越好
-
减少微调阶段所需数据和训练时间,如零样本和少样本迁移
-
突破传统AI模型难以泛化到其他任务上的局限性
-
代理任务训练方式无需人工标注,降低标注成本
-
大量证据表明这些预训练的表示可以很好地推广到各种下游任务
-
-
大规模预训练的缺点:
-
数据
-
试错成本
-
算力资源
-
技术支持
-
-
根据代理任务可以分成:(绿色是NLP)
- 基于预测Prediction
- 掩码
- Mask Language Modeling (MLM)
- roberta
- Language Model(LM)
- Mask Image Modeling (MIM)
- context encoders 擦除中间一大块,也探讨了不同擦除方式
- BEiT[2021] 掩码部分预测离散视觉标记 SOTA
- MAE[2021]
- simMM
- MAE+层次Transformer
- MAE+多模态
- Mask Frame Modeling(MFM)
- Mask Language Modeling (MLM)
- 数据变换预测
- Rotation 识别角度
- Colorization 预测颜色
- Replace Token Detection(RTD)
- 其他
- relative location 预测两个patch相对位置
- DAE?
- 不清楚分类
- Jigsaw[2017]?
- Position[2015]?
- Cutout[2015]
- 掩码
- 基于对比Contrastive 类间差异
- CL
- InfoNCE[2017]
- CPC[2019]
- MoCo v1[2019] 队列增加负样本,实现SOTA
- MoCo v2[2020] 验证SimCLR提出的大数据和非线性层
- MoCo v3[2021] 结合ViT,不要队列,对称损失
- SimCLR v1[2020] 数据增强重要,添加非线性层,大batch
- SimCLR v2
- BYOL[2020] 双网络,仅正样本SOTA
- DeepCluster
- SwAV[2020] 在线聚类损失、multi-crop
- SimSiam[2020] 总结前人,不要负样本、不要大batch,不要动量编码器,SOTA
- SimCSE
- ITM
- CLP
- 其他
- DINO
- SimSias
- CL
- 基于预测Prediction
参考
https://zhuanlan.zhihu.com/p/470914640 介绍了一些pretext task自监督方法【粗略看完】
https://zhuanlan.zhihu.com/p/474847821 介绍了一些对比学习方法【没看】
https://zhuanlan.zhihu.com/p/367290573 介绍对比学习【没看】
https://juejin.cn/post/7044445669805228063 oppo预训练 【没看】
https://liuquncn.github.io/talks/20211013-CCAI-NLP-Forum/Thoughts-of-Pretrained-Big-Models.pdf
https://wxb.xzdw.gov.cn/xxh/xxhgzdt/202206/t20220616_253939.html
https://developer.baidu.com/article/detail.html?id=295106【总
https://www.cnii.com.cn/gxxww/rmydb/202206/t20220616_388934.html【总
https://zhuanlan.zhihu.com/p/485925038【迁移学习】
https://ai.baidu.com/ai-doc/BML/Xkhymkgm4【一些预训练模型】
https://www.csdn.net/tags/OtDaYg5sMzIyMTEtYmxvZwO0O0OO0O0O.html【预训练模型】
https://zhuanlan.zhihu.com/p/526265431【视觉其他大模型】
https://github.com/sxontheway/Keep-Learning/blob/master/Research/pictures/contrastive_learning_summary.pdf 【介绍Moco等对比学习,没看】
问题
预训练的方法划分到底是啥
CLIP
CLIP[1]动机:自然语言能够表达更广泛的视觉概念,能否直接从原始文本中学习关于图像的知识?
- 视觉模型往往预测一组固定类别的对象,而其它视觉概念需要额外的标注数据来训练,限制了其通用性和实用性。
- NLP的GPT-3证明从网络收集的文本数据可以超过人工标注的数据。
代码:https://github.com/openai/CLIP
从文本学习图像表示的发展
-
ConVIRT[2]:医学图像往往依赖ImageNet迁移权重或从文本报告中基于规则提取标签,ConVIRT通过双塔结构以对比学习方式让两路的representation尽可能一致。
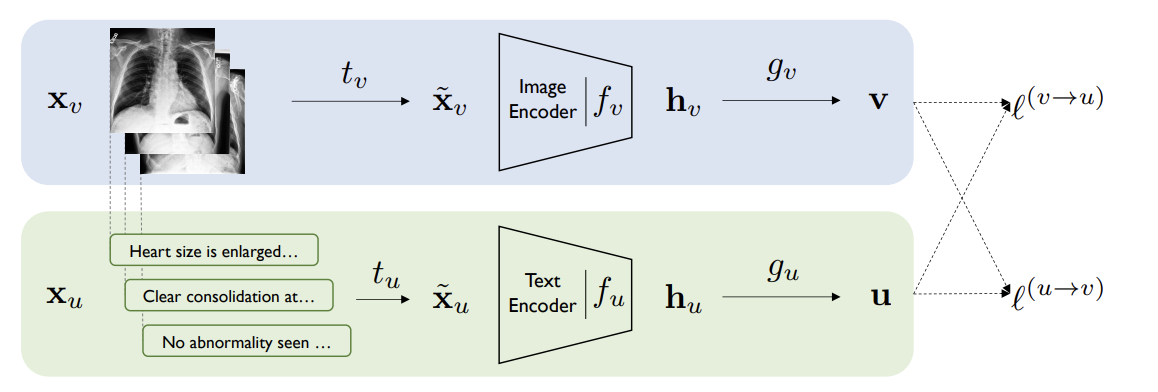
CLIP原理
CLIP: 在4亿互联网的图像-文本对数据上,CLIP联合训练图像encoder和文本encoder,预测哪个文本和哪个图像最匹配。给定N个图像文本对,其中N个正样本对,N^2-N个负样本对,通过对称交叉熵损失最大化图像和文本正样本对的余弦相似度。
- 4亿互联网文本图像对数据集WebImageText(WIT)
- 500000个query
- 改进的ConVIRT
- 随机初始化、改成线性projection、去掉文本采样、只做Resize和Crop
- 温度系数,控制softmax中logits范围,可学习,不作为超参数
- Text encoder: GPT-2 Transformer
- Image encoder: ResNet, ViT
- 任务难度:Transformer Language Model(Image Caption) > Bag of Words Prediction > Bag of Words Contrastive (CLIP),CLIP 选用了难度最低的任务反而训练效率更高,这是因为训练数据所包含的 text-image pair 从互联网收集来的,它们存在一噪音,也就是说并不完全匹配。这个时候适当的降低训练目标,反而能取得更好的收敛
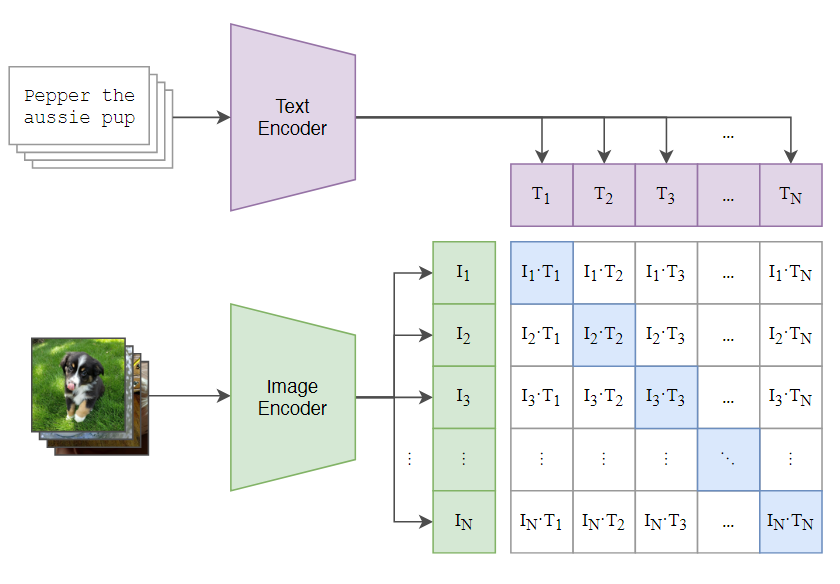 |
 |
clip
image ->卷积-》class_embedding+position_embedding->proj
text->token_embedding->postional_embeding->proj
norm
CLIP zero-shot迁移能力
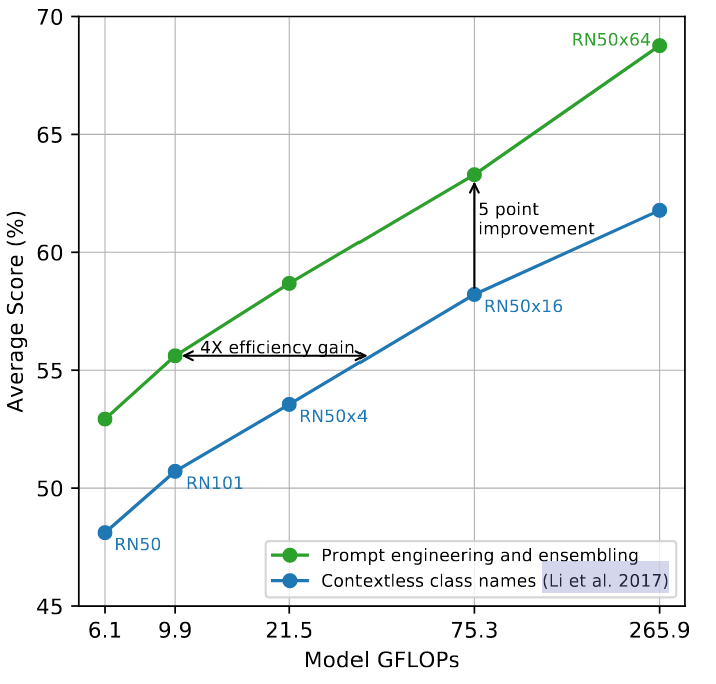
- 测试分类时,把标签填到如“a photo of {xxx}"形成句子,称Prompt工程
- 设计Prompt engineering可以提升效果(+5%)
- CLIP把分类转换成跨模态检索任务,类别不在固定,可扩展
- 图文检索
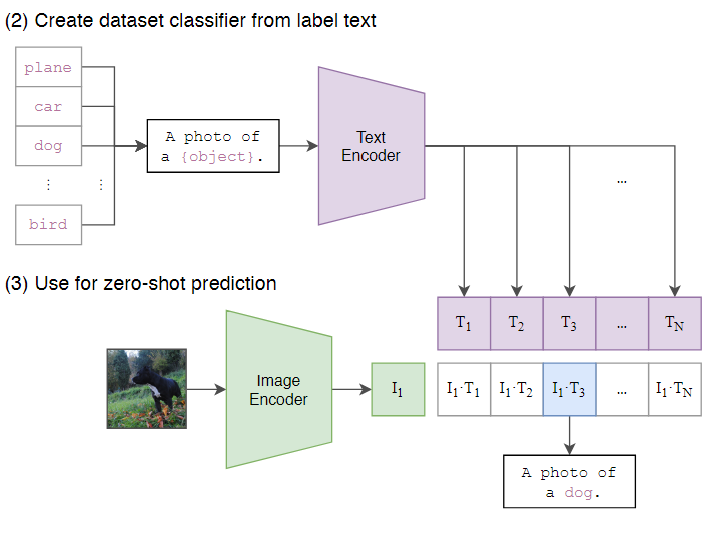 |
 |
CLIP结论
- 构建了图像文本之间的桥梁
- 大规模大模型能学习到泛化强的模型,可以用于多种下游任务:图像分类、图文检索等
- zero-shot
- 达到ImageNet全监督训练的ResNet-50性能
- 通用任务表现好
- 但很多任务比不上SOTA方法
- 细分类、OCR、预训练未见过的任务效果不好
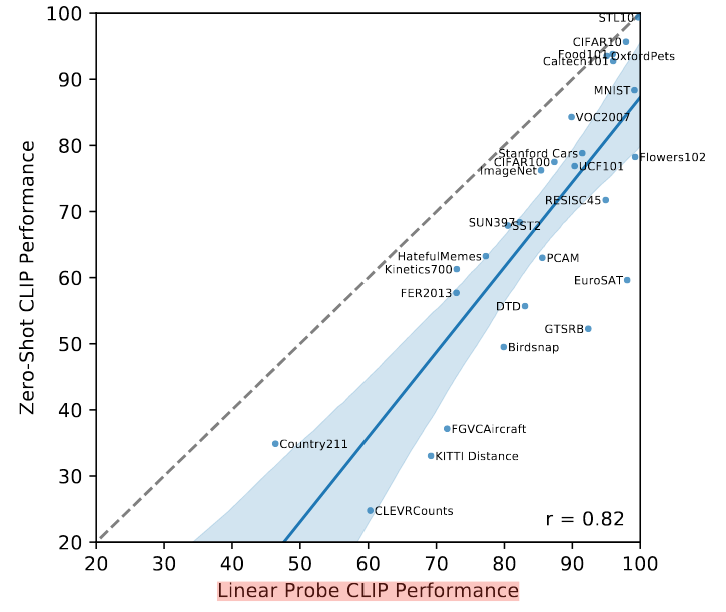
- linearprobe
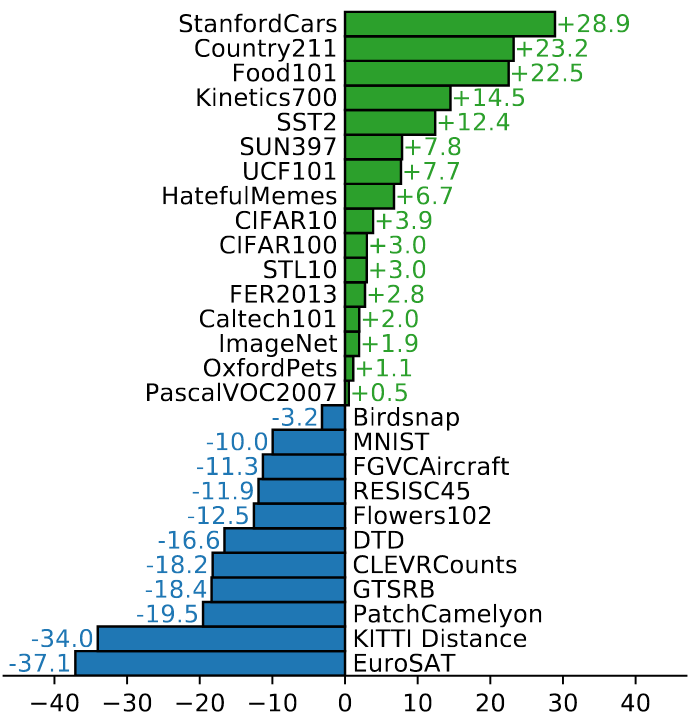
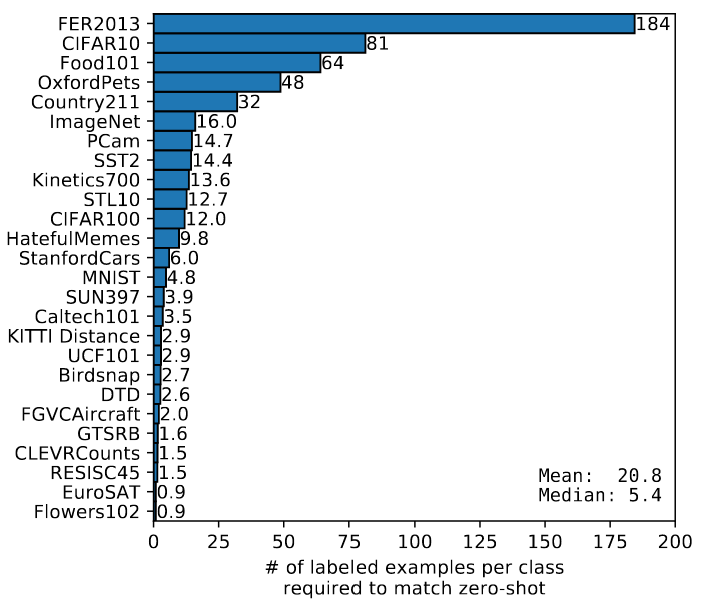
- few-shot需要一些样本才能和zero-shot持平,说明通过自然语言学到的视觉概念比少样本linearprobe学到的要好。
- zero-shot和全部样本训练有10%-25%的提升空间
 |
 |
 |
- 生成模型:DALL-E、StyleCLIP、CLIPDraw、CLIPasso、VQGAN-CLIP、CLIP-GEN
- 语义模型:LSeq、GroupViT
- 目标检测:ViLD、GLIP
- 动作识别:ActionCLIP
- 视频段落匹配:CLIP4clip
- 3D领域:PointCLIP
- 深度信息:DepthCLIP
ITM后续发展
- ALIGN(更大规模数据和EfficientNet encoder)
参考
- https://zhuanlan.zhihu.com/p/486857682 介绍CLIP,不错【大概看完】
- https://jishuin.proginn.com/p/763bfbd71c2f 介绍CLIP和发表自己看法 【大概看完】
- https://iii.run/archives/add2d45c7267.html 介绍CLIP数据集等特色【大概看完,可以再看】
- https://zhuanlan.zhihu.com/p/427740816 简略介绍CLIP 【大概看完】
- https://aitechtogether.com/article/39432.html 简略介绍CLIP 【大概看完】
- https://blog.csdn.net/u012193416/article/details/125891924 简略介绍CLIP 【大概看完】
- https://www.zhihu.com/question/438649654 知乎CLIP看法【没看完】
- https://cloud.tencent.com/developer/article/1902815 介绍CLIP4clip 【没看】
- https://www.cvmart.net/community/detail/5815 ActionCLIP 【没看】
MAE
MAE[3]动机:为什么NLP领域BERT的MLM掩码方式没有成功应用于CV领域
- 结构上,BERT基于transformer架构难迁移到CV,但是ViT已解决。
- 信息密度上,图像存在冗余信息,丢弃小部分容易从周围恢复。
- 单词预测是高语义任务,所以decoder只需一层MLP,但不适合低语义的图像重建任务。
MIM发展
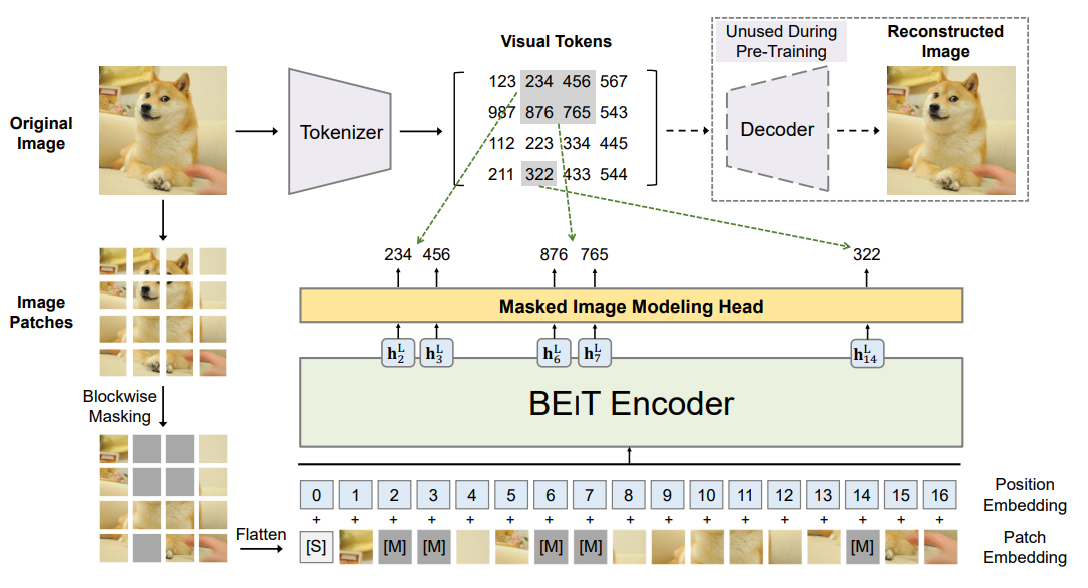
BEiT[4]:输入图像随机掩码部分patch,通过ViT基于未掩码图像patch来恢复掩码图像patch,重建目标不是原始像素,而是通过dVAE得到的discrete visual tokens离散视觉标记。大约掩码40%。
 |
MAE原理
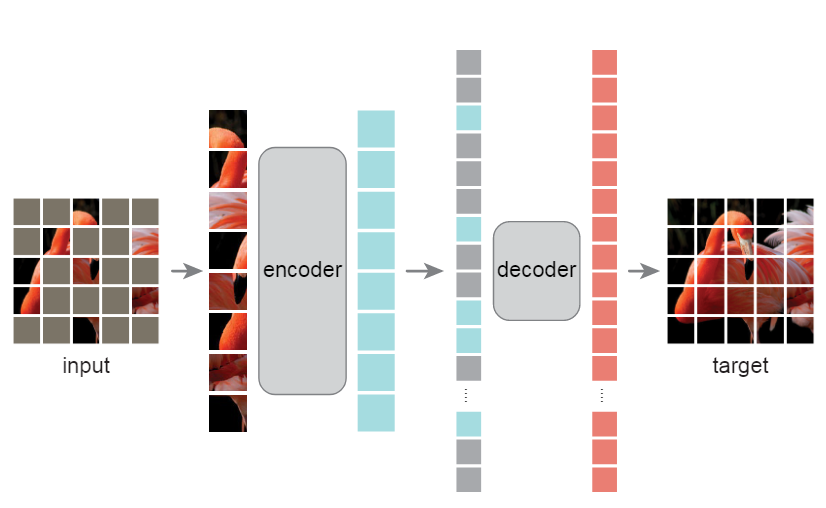
MAE简化了整体训练逻辑,采用非对称encoder-decoder的结构,随机mask输入图像的部分patch,对其进行重建,只计算mask部分的MSE损失。
-
非对称encoder-decoder结构
- encoder仅计算非掩码patch,加速训练3倍以上。
- decoder由transformer blocks组成的轻量级网络,同时对潜在表示和mask token进行解码。
- mask token是共享的可学习向量。
-
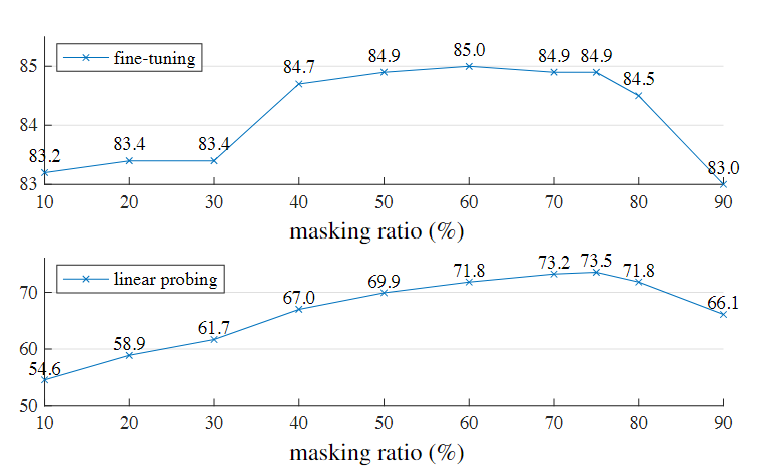
mask比例达到75%时,模型更关注全局信息,而不是简单插值。
 |
 |
MAE流程
MAE
finetune
image ->patch_embedding-》class_token+position_embedding
train
image ->patch_embedding-》position_embedding-》mask->class_token+pos_emb
mask_token+pos_emb
MAE结论
- mask
- mask75%最好,且掩码比例高于其它方法
- 随机掩码效果最好
- 非对称encoder-decoder
- encoder处理全部patch,效果反而差,linear probe下降14%
- 解码器与编码器相比,计算量 <10%。虽然全部patch由轻量级解码器处理,但耗时少
- decoder深度对linearprobe影响大(8%提升幅度),对finetue影响小
- 重建目标
- 每个mask patch的归一化像素值作为重建目标在局部增强对比度,可以提高表示质量(+0.5%)
- BEiT的dVAE得到的离散视觉标记作为重建目标效果比归一化像素值差,还增加开销
- linearprobe和finetune
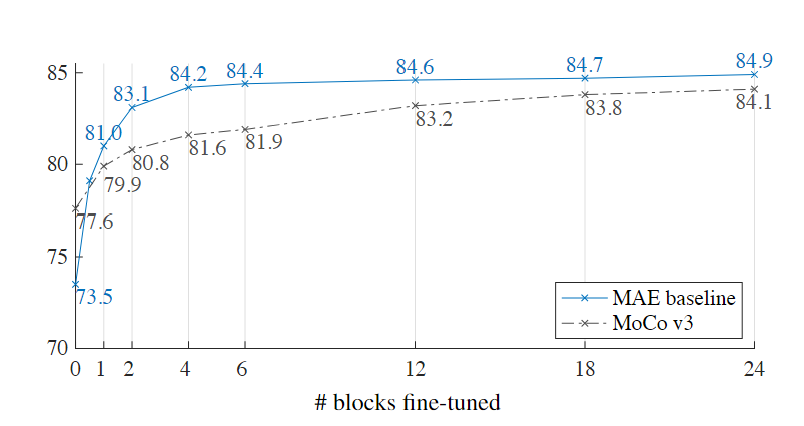
- finetune优于从头训练,且耗时少
- linearprobe和finetune很大程度是不相关的
- finetune最后几层:一个MLP(79.1%),一个Transformer(81.0%),比linearprobe(73.5%)要好
- MAE具有很强的非线性特征,MAE认为linearprobe与迁移学习性能的相关性不大,线性可分性并不是预训练唯一指标
- 下游任务迁移
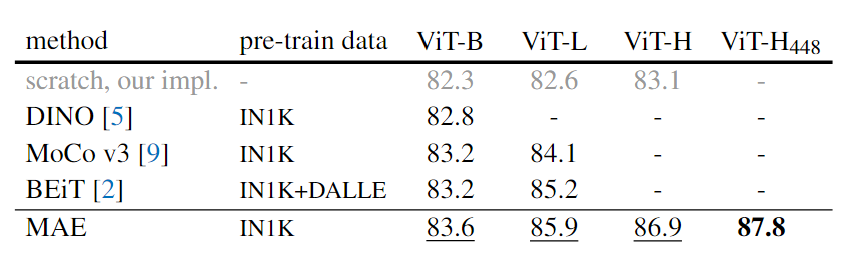
- ViT-Huge在ImageNet-1k达到87.8%的top1准确率
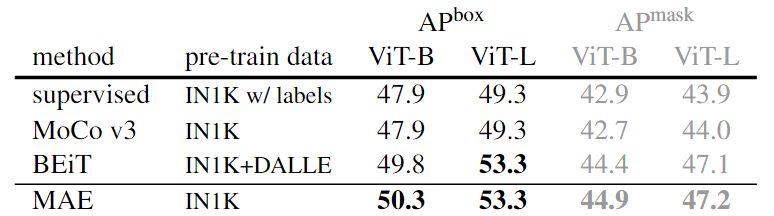
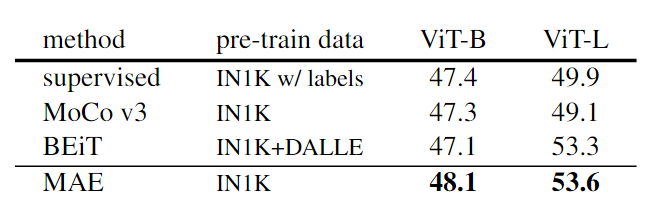
- 对象检测、实例分割和语义分割的迁移学习,比有监督的Mask-RCNN,UperNet、自监督的BEiT效果好
- 其它预训练方法
- 比较了不同自监督方法和模型大小,模型越大不同方法差距越大,表明更大模型减少过度拟合
- MAE总预训练时间仍少于所有其他方法
- 与BEiT相比,MAE 更准确、简单、更快
- 非对称结构+高mask比例,减少计算量和内存,同时提升准确率,可以训练更大模型和更大batch加速训练
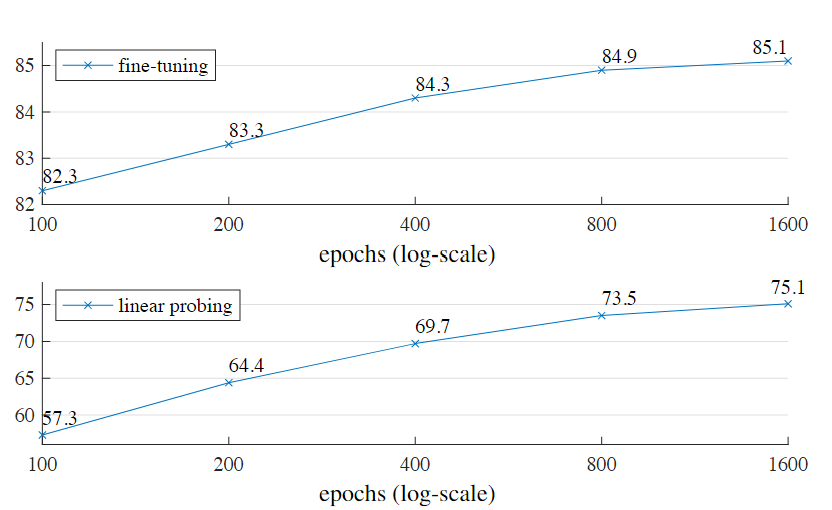
- 随着训练代数增加,准确率稳步提高。1600 epoch时,仍未饱和
 |
 |
 |
 |
 |
 |
MAE发展和应用
- MAE适应不同结构ViT
- 层次Transformer的MixMM
- 金字塔结构ViT的Uniform Masking
- MAE适应不同领域
- 视频VideoMAE
- 多模态M3MAE
- MultiMAE
- 音频MAE that listen
- 时间序列TSFormer
- 图GraphMAE
MIM后续发展
- MAE同期工作:SimMIM(BEiT去dVAE)、MaskFeat(重建目标HIOG特征)、PeCo(dVAE训练加入Perceptual loss)、IBOT(dVAE tokenizer方式改成在线训练)
- CAE(认为MAE的decoder也负责了部分表征学习,没用充分挖掘encoder能力)
参考
- https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/125270007
- https://zhuanlan.zhihu.com/p/528720386
- https://zhuanlan.zhihu.com/p/432984431【MAE实验】
- https://picture.iczhiku.com/weixin/message1639795018014.html【MAE】
- https://aistudio.baidu.com/aistudio/projectdetail/3465622【mae代码
- https://www.51cto.com/article/718613.html【mae各个领域
- https://zhuanlan.zhihu.com/p/445561242【beit和MAE】
- https://wanggrun.github.io/projects/fast/fast021 BEiT
- https://zhuanlan.zhihu.com/p/467399602【CAE】
- https://www.qbitai.com/2022/02/32835.html 【CAE】
- https://zhuanlan.zhihu.com/p/475952825【MIM】simmim 同期
- https://zhuanlan.zhihu.com/p/480196600【MIM】
- https://jishuin.proginn.com/p/763bfbd78a55 【ConvMAE】
对比
- MIM方法更关注每个patch,而对比学习方法更关注图像主体语义(如图CAE和MoCov3热力图对比)
| 训练数据 | 数据构建 | 训练时间 | encoder | loss | 任务 | |
|---|---|---|---|---|---|---|
| CLIP | 4亿网络图像文本对 | 图像文本对,prompt构建 | ResNet:592V00需18天 ViT:256V00需12天 | ResNet,ViT | 对称交叉熵损失 | 多模态检索 |
| MAE | ImageNet-1K | 图像 | ViT-L:128TPU-v3需31天 | ViT | MSELoss |

参考资料
Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021. ↩︎
Zhang, Yuhao, et al. “Contrastive learning of medical visual representations from paired images and text.” arXiv preprint arXiv:2010.00747 (2020). ↩︎
He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. ↩︎
Bao, Hangbo, Li Dong, and Furu Wei. “Beit: Bert pre-training of image transformers.” arXiv preprint arXiv:2106.08254 (2021). ↩︎
